初识 Hadoop
前言
本系列文章是基于《大数据技术基础》与 10 小时入门大数据 课程,如果有兴趣可以先阅读该书并观看视频教程。本系列文章中所用到的软件版本及其下载地址如下:
环境准备
配置网络
此篇文章所使用的 CentOS 环境均是使用 VMware 15 虚拟的,具体安装教程请查看 使用 VMware 15 安装虚拟机和使用 CentOS 8,此处不再赘述。安装好一个节点之后,我们可以采用“虚拟机克隆”的方式,直接完成另外两个节点系统的安装。
虚拟机的网络配置采用 DHCP 自动分配模式,每台机器的 IP 地址可以通过命令 ip address 或 ifconfig 查看,其中 ifconfig 输出如下,第一组配置中 ens33 即为本机网络配置,inet 项对应的即为本机 ip(192.168.61.128)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.61.128 netmask 255.255.255.0 broadcast 192.168.61.255
inet6 fe80::20c:29ff:fe65:9052 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:65:90:52 txqueuelen 1000 (Ethernet)
RX packets 38037 bytes 6542757 (6.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 30479 bytes 16809162 (16.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 23656 bytes 13542580 (12.9 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 23656 bytes 13542580 (12.9 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
virbr0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
ether 52:54:00:d2:b3:31 txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
|
本篇文章中三台集群的 IP 分别如下,下文中不再赘述。
| 主机名 | IP |
|---|
| master | 192.168.61.128 |
| slave1 | 192.168.61.129 |
| slave2 | 192.168.61.131 |
配置 host
以上三台机器要搭建成为集群,就需要让它们互相认识。这个认识的过程是通过 /etc/hosts 文件来实现的。这一步需要修改每一台机器的 hosts 文件,将以下内容分别粘贴到各个机器的 hosts 文件中。
1
2
3
| 192.168.61.128 master
192.168.61.129 slave1
192.168.61.131 slave2
|
配置 JDK
因为 Hadoop 的环境依赖于 Java JDK,所以需要确保虚拟机中已经正确安装了 JDK,除此之外我们还需要将 JDK 地址配置到环境变量中。在本例中,我的 JDK 安装位置是 /usr/java/jdk-14.0.2。
修改 bash_profile
添加以下内容到 .bash_profile 文件末尾:
1
2
| export JAVA_HOME=/usr/java/jdk-14.0.2
export PATH=$JAVA_HOME/bin:$PATH
|
修改完成并保存后,还需要执行 source 命令使环境变量立即生效。
然后即可使用 java -version 检查环境变量是否配置成功,执行结果如下所示。
1
2
3
| java version "14.0.2" 2020-07-14
Java(TM) SE Runtime Environment (build 14.0.2+12-46)
Java HotSpot(TM) 64-Bit Server VM (build 14.0.2+12-46, mixed mode, sharing)
|
配置 SSH 免密钥登录
在 Linux 集群间配置免密钥登录,是 Hadoop 集群运维的基础。以下操作在 master 节点进行,实现从 master 免密钥登录 slave1、slave2 节点。生成 ssh 密钥的命令如下:
生成过程中会有一些提示,一路回车即可。执行结果如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| root@master:/usr/local/software## ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:DC7+sETaazn0f4OVgxozjdw2XM1Tb60cqoaQvDGXpg8 root@master
The key's randomart image is:
+---[RSA 3072]----+
| |
| . |
| . o . ..|
| . o . + . +|
| oo.*S+ . + + |
| =..% @ + . o |
| ..=oE## = o |
| .+==.o = |
| .o..ooo . |
+----[SHA256]-----+
|
接下来需要将生成的公钥上传到 slave1 节点,命令如下:
1
| ssh-copy-id root@slave1
|
首次通过 master 终端将公钥传给 salve 终端,需要输入 slave 节点的登录密码。上述命令中我们是传输到 slave1 的 root 账户下,所以需要输入 root 用户的密码,传送完毕即可实现免密码登录。执行结果如下。
1
2
3
4
5
6
7
8
9
10
| root@master:/usr/local/software## ssh-copy-id root@slave1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@slave1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@slave1'"
and check to make sure that only the key(s) you wanted were added.
|
slave2 节点命令同上,只需更改传送到的节点名称,执行结果如下。
1
2
3
4
5
6
7
8
9
10
| root@master:/usr/local/software## ssh-copy-id root@slave2
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@slave2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@slave2'"
and check to make sure that only the key(s) you wanted were added.
|
现在可以尝试登录子节点 slave1 和 slave2。
成功登录 salve1 节点的提示如下。
1
2
3
4
| root@master:/usr/local/software## ssh root@slave1
Web console: https://slave1:9090/ or https://192.168.61.129:9090/
Last login: Fri Sep 24 14:56:46 2020 from 192.168.61.1
|
完善配置
以下配置均在 master 节点上完成,配置完成后可直接复制到 slave 节点,以免重复劳动。
安装 Hadoop
1
2
3
4
5
| cd /usr/local/software
wget http://mirror.cogentco.com/pub/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1-src.tar.gz
tar -zxvf hadoop-2.10.1-src.tar.gz
cd hadoop-2.10.1-src
mv * ~/hadoop
|
在正式使用 Hadoop 集群之前,我们还需要对其配置文件进行修改。本节中的配置内容请以 官方文档 为准。
Hadoop 的配置文件均存放在 Hadoop 所在目录的 /etc/hadoop/ 文件夹下。
修改配置文件
编辑 core-site.xml
文件 core-site.xml 用来配置 Hadoop 集群的通用属性,包括指定 NameNode 的地址、指定使用 Hadoop 时临时文件的存放路径、指定检查点备份日志的最长时间等。
使用 vim 打开文件:
1
| vim ~/hadoop-2.10.1/etc/hadoop/core-site.xml
|
使用以下内容替换 core-site.xml 中的内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| <?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 namenode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定使用 Hadoop 时临时文件的存放路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/temp</value>
</property>
</configuration>
|
第 69 行配置 fs.defaultFS 的属性为 hdfs://master:9000,master 是主机名;第 1215 行指定 Hadoop 的临时文件夹为 /home/hadoop/temp,此文件夹用户可以自己指定。
编辑 hdfs-site.xml
文件 hdfs-site.xml 用来配置分布式文件系统 HDFS 的属性,包括指定 HDFS 保存数据的副本数量,指定 HDFS 中 NameNode、DataNode 的存储位置等。
使用 vim 打开文件:
1
| vim ~/hadoop-2.10.1/etc/hadoop/hdfs-site.xml
|
使用以下内容替换 hdfs-site.xml 中的内容:
1
2
3
4
5
6
7
8
9
10
| <?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 HDFS 保存数据的副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
|
其中,第 7~8 行,指定 HDFS 文件快的副本数为 1。数据块副本一般为 3 以上,本文章仅作示例,故指定为 1。
编辑 yarn-site.xml
YARN 是 MapReduce 的调度框架。文件 yarn-site.xml 用配置 YARN 的属性,包括指定 NameNodeManager 获取数据的方式,指定 ResourceManager 的地址,配置 YARN 打印工作日志等。
使用 vim 打开文件:
1
| vim ~/hadoop-2.10.1/etc/hadoop/yarn-site.xml
|
使用以下内容替换 yarn-site.xml 中的内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| <?xml version="1.0"?>
<configuration>
<!-- 指定 NameNodeManager 获取数据的方式是 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 指定 YARN 中 ResourceManager 所在的主机名 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
|
其中,第 15~19 行配置了 ResourceManager 所在的主机名,如果不进行配置,将会导致 MapReduce 不能获得资源,任务不能执行。
编辑 mapred-site.xml
文件 mapred-site.xml 主要是配置 MapReduce 的属性,主要是 Hadoop 系统提交的 Map/Reduce 程序运行在 YARN 上。
首先复制一份 mapred-site.xml.template 文件为 mapred-site.xml,然后打开并进行修改。
1
| vim ~/hadoop-2.10.1/etc/hadoop/mapred-site.xml
|
使用以下内容替换 mapred-site.xml 中的内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
| <?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
|
其中,第 5~8 行为 MapReduce 指定任务调度框架为 YARN。
编辑 slaves
slaves 文件为 Hadoop 提供了子节点的主机名。
1
| vim ~/hadoop-2.10.1/etc/hadoop/slaves
|
使用以下内容替换 slaves 中的内容:
复制文件到子节点
使用下面的命令将 Hadoop 文件复制到其他节点,本文中为 slave1 和 slave2,命令如下:
1
2
3
| cd ~/hadoop
scp -r hadoop-2.10.1 root@slave1:~/hadoop/
scp -r hadoop-2.10.1 root@slave2:~/hadoop/
|
配置 Hadoop 环境变量
注意,此操作需要同时在所有节点(master,slave1,slave2)都执行一次,操作命令如下:
将以下内容追加到 .bash_profile 文件末尾:
1
2
3
| #HADOOP
export HADOOP_HOME=/root/hadoop/hadoop-2.10.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
|
然后执行下列命令使环境变量生效:
创建临时文件存放目录
我们在 core-site.xml 文件中指定了 Hadoop 临时文件存放路径,但是文件夹并没有创建,此操作需要同时在所有节点(master,slave1,slave2)都执行一次,操作命令如下:
1
| mkdir /home/hadoop/temp
|
启动集群
格式化文件系统
注意,格式化仅需要在第一次使用 Hadoop 集群时进行,后续使用时无需格式化,并且在使用过程中进行格式化,所有文件将会丢失。此操作需要在 master 节点上进行,执行如下命令:
启动 Hadoop 集群
Hadoop 启动或停止服务的脚本均存放在 sbin 目录中,所以切换到 /home/hadoop/hadoop-2.10.1/sbin 目录下,执行以下命令:
需要注意的是,在启动过程中,Hadoop 会提示这样的启动方式已经过时,使用如下启动方式即可规避过时提示:
1
2
| start-dfs.sh
start-yarn.sh
|
查看进程是否启动成功
在 master 节点终端执行 jps 命令,在打印结果中会看到四个进程,分别是 NodeManager、SecondaryNameNode、ResourceManager、Jps。如果出现了这四个进程表示启动成功。结果如下:
1
2
3
4
5
| root@master:~/hadoop/hadoop-2.10.1/sbin## jps
17874 NameNode
18070 SecondaryNameNode
18281 ResourceManager
18554 Jps
|
此时在 slave1 和 slave2 的节点的终端执行 jps 命令,在输出结果中会看到三个进程,分别是 Jps、NodeManager、DataNode,如果出现了这三个进程表示子节点进程启动成功。结果如下:
1
2
3
4
| root@slave1:~## jps
15776 NodeManager
15639 DataNode
16106 Jps
|
查看 WebUI
Hadoop 页面
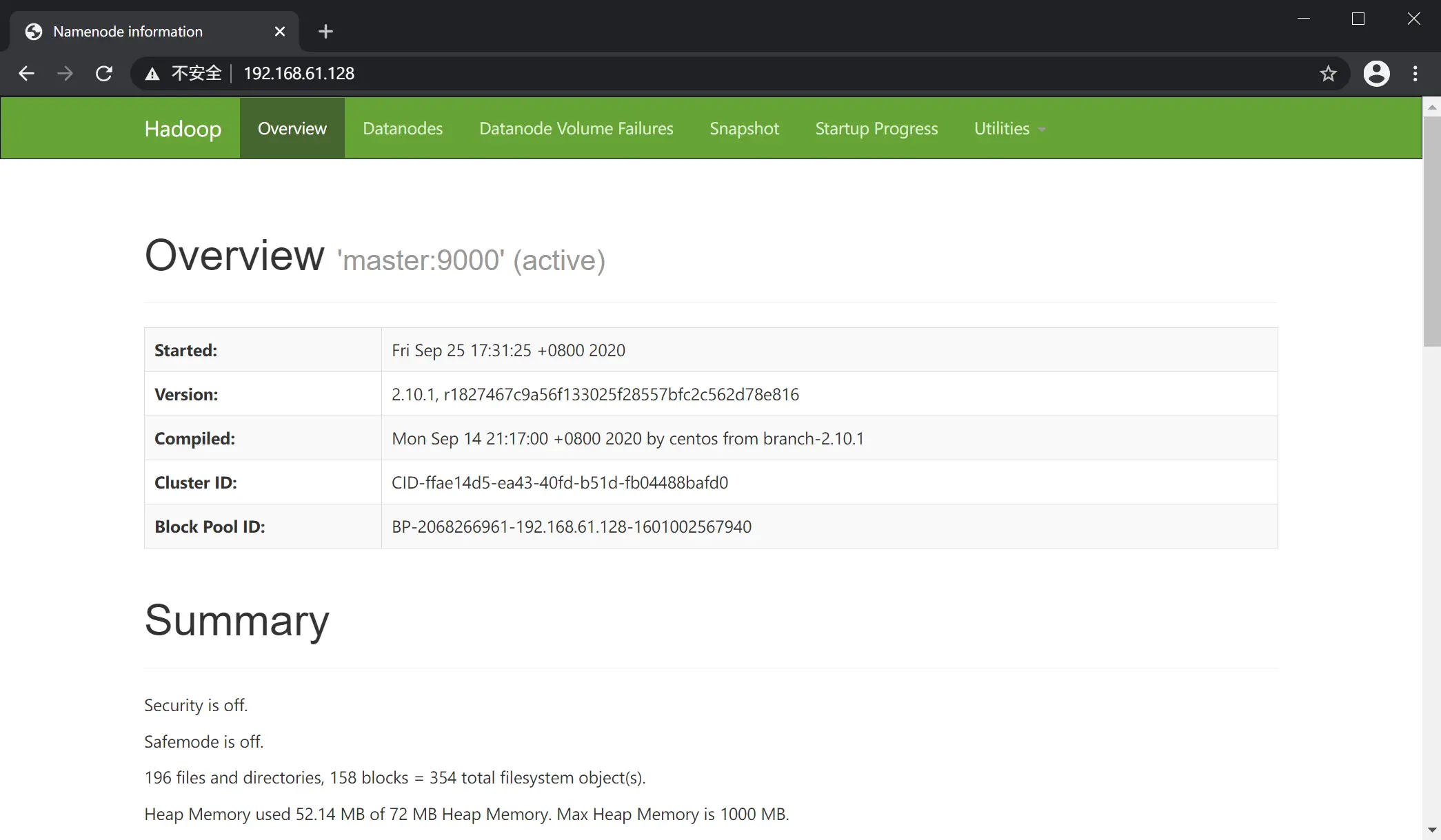
如果要在宿主机上访问虚拟机 master 节点的 WebUI,需要先将虚拟机的防火墙关闭(此处仅仅是做示例,生产环境不建议这么做),然后访问虚拟机 master 节点 IP:50070 即可。
防火墙相关命令如下:
1
2
3
4
5
6
7
8
| ## 暂时关闭防火墙
systemctl stop firewalld
## 永久关闭防火墙
systemctl disable firewalld
## 启用防火墙
systemctl enable firewalld
|
例如本例中 master 节点地址为 192.168.61.128,则访问 192.168.61.128:50070,页面如下图:
YARN 页面
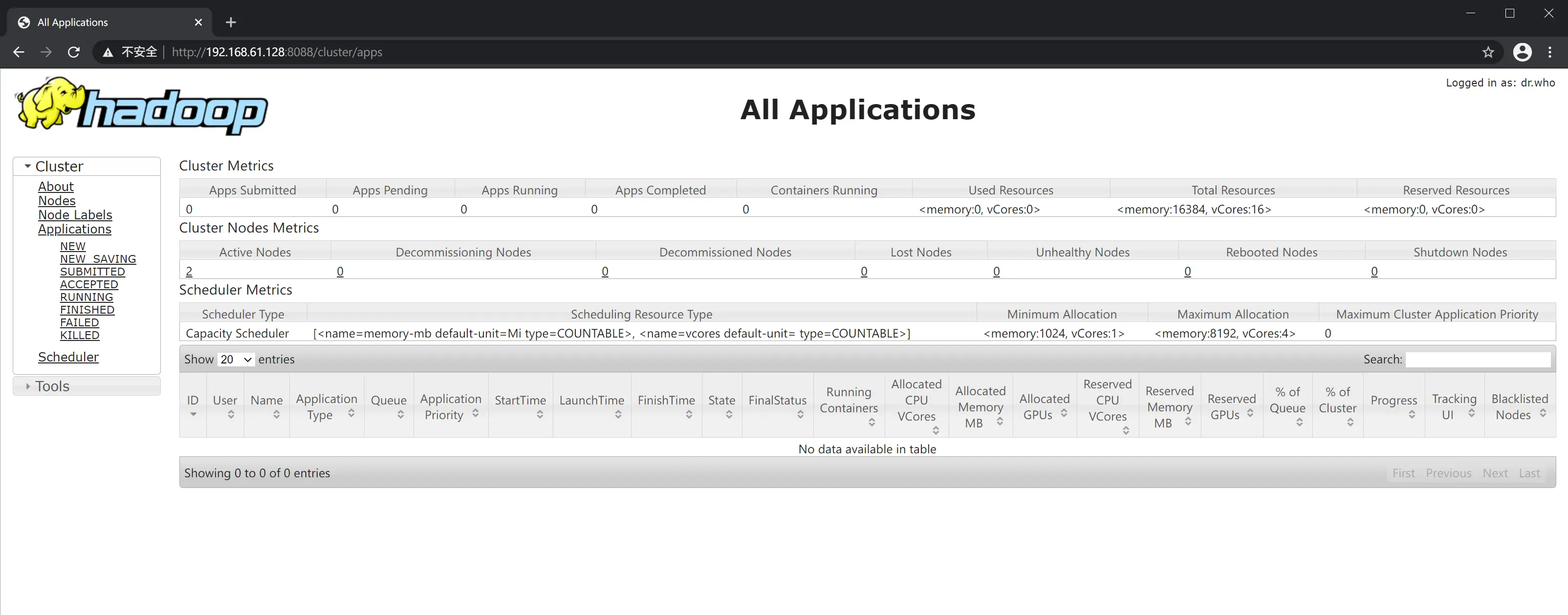
如上例,与 Hadoop 管理页面不同的是,YARN Web 页面地址端口是 8088,页面如下图:
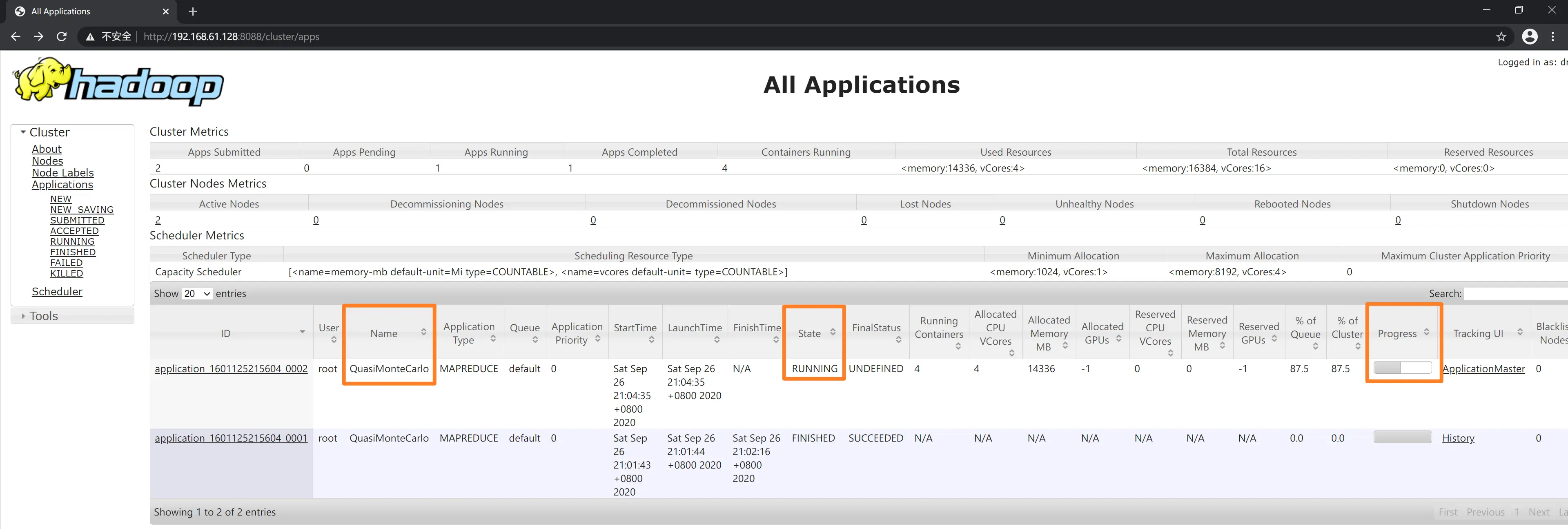
运行实例
在 Hadoop 自带的 examples 中有一种利用分布式系统计算圆周率的方法,采用的是拟蒙特卡罗(Quasi-Monte Carlo)算法来对 $ \pi $ 的值进行估算。下面通过运行该程序来检验 Hadoop 集群是否安装配置成功。
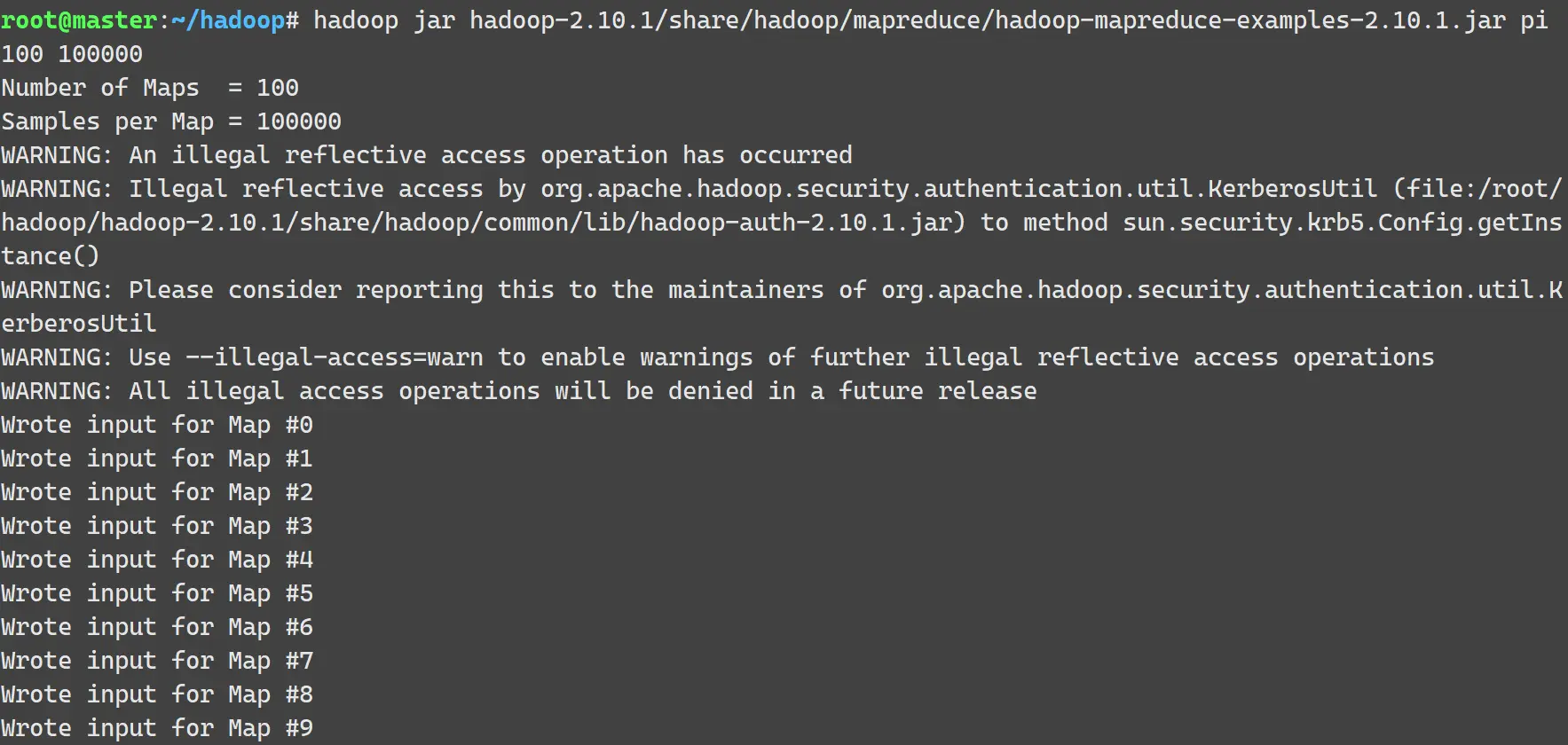
在 master 节点终端中执行下面的命令:
1
| hadoop jar hadoop-2.10.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar pi 100 100000
|
Hadoop 的命令类似 Java 命令,通过 jar 指定要运行的程序所在的 jar 包 hadoop-mapreduce-examples-2.10.1.jar。参数 pi 表示需要计算的圆周率 $ \pi $。后面两个参数中,100 是指要运行 100 次 map,100000 表示每个 map 的任务次数,即每个节点要模拟飞镖 100000 次。执行过程及结果如下图:
1
2
| Job Finished in 131.634 seconds
Estimated value of Pi is 3.14158440000000000000
|
至此,Hadoop 环境配置完成。
备注
如果在执行 mapreduce 任务中报错如 此问题 的描述,参考 此篇文章,需要在 mapred-site.xml 文件中添加下列配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| <property>
<name>mapreduce.map.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>8192</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx3072m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx6144m</value>
</property>
|