HDFS 文件管理
本文所有代码均可在 https://github.com/jinggqu/HDFSOperations 查看。
通过命令行访问 HDFS
命令行是最简单、最直接操作文件的方式。这里介绍通过诸如读取文件、新建目录、移动文件、删除数据、列出目录等命令来进一步认识 HDFS。也可以输入 hadoop fs -help 命令获取每个命令的详细帮助。若熟悉 Linux 命令,Hadoop 命令看起来非常直观且易于使用。
对文件和目录的操作
通过命令行对 HDFS 文件和目录的操作主要包括:创建、浏览、删除文件和目录,以及从本地文件系统与 HDFS 文件系统互相拷贝等。常用命令格式如下。
| |
修改权限或用户组
HDFS 提供了一些命令可以用来修改文件的权限、所属用户以及所属组别,具体格式如下:
hadoop fs -chmod [-R] <MODE [,MODE]...|OCTALMODE> PATH...
改变 HDFS 上路径为 PATH 的文件的权限,R 选项表示递归执行该操作。
例如:hadoop fs -chmod -R +r /user/test,表示将 /user/test 目录下的所有文件赋予读的权限hadoop fs -chown [-R][OWNER][:[GROUP]]PATH...
改变 HDFS 上路径为 PATH 的文件的所属用户,-R 选项表示递归执行该操作。
例如:hadoop fs -chown -R hadoop:hadoop /user/test,表示将 /user/test 目录下所有文件的所属用户和所属组别改为 hadoophadoop fs -chgrp [-R] GROUP PATH...
改变 HDFS 上路径为 PATH 的文件的所属组别,-R 选项表示递归执行该操作。
例如:hadoop fs -chown -R hadoop /user/test表示将 /user/test 目录下所有文件的所属组别改为 hadoop
其他命令
HDFS 除了提供上述两类操作之外,还提供许多实用性较强的操作,如显示指定路径上的内容,上传本地文件到 HDFS 指定文件夹,以及从 HDFS 上下载文件到本地等命令。
hadoop fs -tail [-f] <file>
显示 HDFS 上路径为 <file> 的文件的最后 1KB 的字节,-f 选项会使显示的内容随着文件内容更新而更新。
例如:hadoop fs -tail -f /user/test.txthadoop fs -stat [format] <path>
显示 HDFS 上路径为 <path> 的文件或目录的统计信息。格式为:%b 文件大小,%n 文件名,%r 复制因子,%y、%Y 修改日期。
例如:hadoop fs -stat %b %n %o %r /user/testhadoop fs -put <localsrc>...<dt>
将 <localsrc> 本地文件上传到 HDFS 的 <dst> 目录下。
例如:hadoop fs -put /home/hadoop/test.txt /user/hadoophadoop fs -count [-q] <path>
显示 <path> 下的目录数及文件数,输出格式为“目录数 文件数 大小 文件名”,加上 -q 可以查看文件索引的情况。
例如:hadoop fs -count /hadoop fs -get [-ignoreCrc] [-crc] <src> <localdst>
将 HDFS 上 <src> 的文件下载到本地的 <localdst> 目录,可用 -ignorecrc 选项复制 CRC 校验失败的文件,使用 -crc 选项复制文件以及 CRC 信息。
例如:hadoop fs -get /user/hadoop/a.txt /home/hadoophadoop fs -getmerge <src> <localdst> [addnl]
将 HDFS 上 <src> 目录下的所有文件按文件名排序并合并成一个文件输出到本地的 <localdst> 目录,addnl 是可选的,用于指定在每个文件结尾添加一个换行符。
例如:hadoop fs -getmerge /user/test /home/hadoop/ohadoop fs -test -[ezd] <path>
检查 HDFS 上路径为 <path> 的文件。-e 检查文件是否存在,如果存在则返回 0。-z 检查文件是否为 0 字节,如果是则返回 0。-d 检查路径是否是目录,如果是则返回 1,否则返回 0。
例如:hadoop fs -test -e /user/test.txt
通过 Java API 访问 HDFS
使用 Hadoop URL 读取数据
要从 Hadoop 文件系统读取数据,最简单的方法是使用 java.net.URL 对象打开数据流,从中读取数据。
让 Java 程序能够识别 Hadoop 的 HDFS URL 方案还需要一些额外的工作,这里采用的方法是通过 org.apache.hdfs.FsUrlStreamHandlerFactor 实例调用 java.net.URL 对象的 setURLStreamHandlerFactory 实例方法。每个 Java 虚拟机只能调用一次这个方法,因此通常在静态方法中调用。下述范例展示的程序以标准输出方式显示 Hadoop 文件系统中的文件,类似于 UNIX 中的 cat 命令。
| |
编译代码,导出为 URLCat.jar 文件,并在 /user/hadoop/ 中准备一个测试文件 test,然后执行命令:
| |
执行完成后可以在屏幕上看到 /user/hadoop/test 文件中的内容。该程序是从 HDFS 读取文件的最简单的方式,即用 java.net.URL 对象打开数据流。其中,第 8~10 行静态代码块的作用是设置 URL 类能够识别 Hadoop 的 HDFS URL。第 16 行 IOUtils 是 Hadoop 中定义的类,调用其静态方法 copyBytes 实现从 HDFS 文件系统拷贝文件到标准输出流。4096 表示用来拷贝的缓冲区大小,false 表示拷贝完成后不关闭拷贝源。
通过 FileSystem API 读取数据
在实际开发中,访问 HDFS 最常用的类是 FileSystem 类。Hadoop 文件系统中通过 Hadoop Path 对象来定位文件。可以将路径视为一个 Hadoop 文件系统 URI,如 hdfs:localhost/user/hadoop/test。FileSystem 是一个通用的文件系统 API,获取 FileSystem 实例有下面几个静态方法:
| |
下面分别给出几个常用操作的代码示例。
读取文件
| |
上述代码直接使用 FileSystem 以标准输出格式显示 Hadoop 文件系统中的文件。
第 4 行产生一个 Confguation 类的实例,代表了 Hadoop 平台的配置信息,并在第 5 行作为引用传递到 FileSystem 的静态方法 get 中,产生 FileSystem 对象。
第 9 行与上例类似,调用 Hadoop 中 IOUtils,并在 finally 字中关闭数据流,同时也可以在输入流和输出流之间复制数据。copyBytes 方的最后两个参数,第一个设置用于复制的缓冲区大小,第二个设置复制结束后是否关闭数据流。
写入文件
| |
创建目录
| |
删除文件或目录
| |
使用 FileSystem 的 delete() 方法可以永久性删除文件或目录。如果要递归删除文件夹,则需要将其第二个参数设为 true。
列出文件或目录
| |
文件系统的重要特性是提供浏览和检索其目录结构下所存文件与目录相关信息的功能。 FileStatus 类封装了文件系统中文件和目录的元数据,例如文件长度、块大小、副本、修改时间、所有者以及权限信息等。编译运行上述代码后控制台将会打印出 /user 目录下的名称或者文件名。
小结
HDFS 组成部分
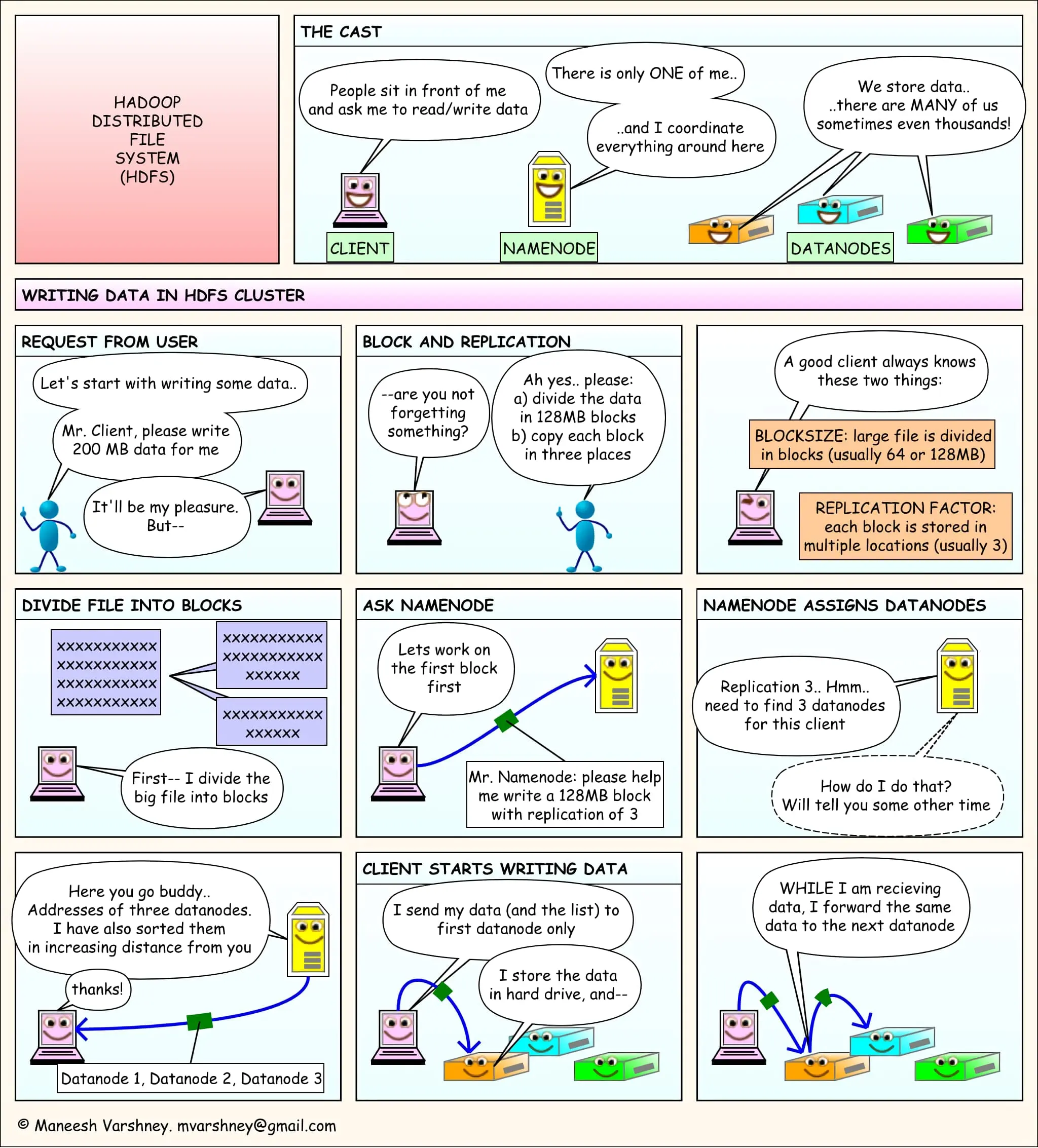
- HDFS 是一个分布式文件存储系统
- Client 提交读写请求(拆分 blocksize)
- NameNode 全局把控(存储数据位置)
- DataNode 存储数据(将数据存储进去,且以 Pipeline 的方式把数据写完)
HDFS 数据交互
写入数据
- 使用 HDFS 提供的客户端 Client,向远程的 NameNode 发起 RPC 请求
- NameNode 会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常
- 当客户端开始写入文件的时候,客户端会将文件切分成多个 packets,并在内部以数据队列 data queue(数据队列) 的形式管理这些 packets,并向 NameNode 申请 blocks,获取用来存储 replicas 的合适的 DataNode 列表,列表的大小根据 NameNode 中 replication(副本份数)的设定而定
- 开始以 pipeline(管道)的形式将 packet 写入所有的 replicas 中。客户端把 packet 以流的方式写入第一个 DataNode,该 DataNode 把该 packet 存储之后,再将其传递给在此 pipeline 中的下一个 DataNode,直到最后一个 DataNode,这种写数据的方式呈流水线的形式
- 最后一个 DataNode 成功存储之后会返回一个 ack packet(确认队列),在 pipeline 里传递至客户端,在客户端的开发库内部维护着 “ack queue”,成功收到 DataNode 返回的 ack packet 后会从 “data queue” 移除相应的 packet
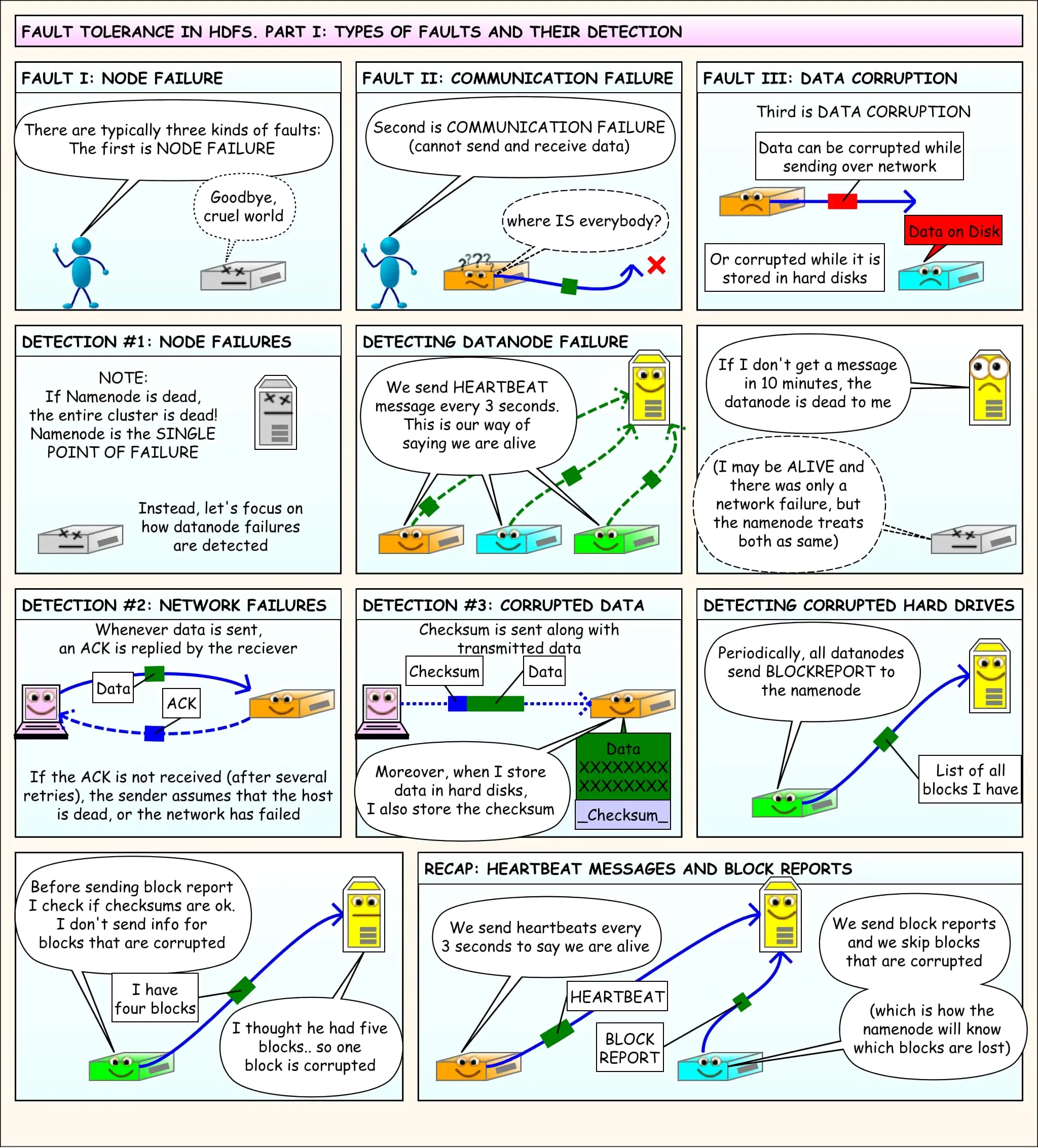
- 如果传输过程中,有某个 DataNode 出现了故障,那么当前的 pipeline 会被关闭,出现故障的 DataNode 会从当前的 pipeline 中移除,剩余的 block 会继续剩下的 DataNode 中继续以 pipeline 的形式传输,同时 NameNode 会分配一个新的 DataNode,保持 replicas 设定的数量。
- 客户端完成数据的写入后,会对数据流调用 close() 方法,关闭数据流
- 只要写入了 dfs.replication.min(最小写入成功的副本数)的复本数(默认为 1),写操作就会成功,并且这个块可以在集群中异步复制,直到达到其目标复本数(dfs.replication 的默认值为 3),因为 NameNode 已经知道文件由哪些块组成,所以它在返回成功前只需要等待数据块进行最小量的复制
读取数据
- 客户端调用 FileSystem 实例的 open 方法,获得这个文件对应的输入流 InputStream
- 通过 RPC 远程调用 NameNode,获得 NameNode 中此文件对应的数据块保存位置,包括这个文件的副本的保存位置(主要是各 DataNode 的地址)
- 获得输入流之后,客户端调用 read 方法读取数据。选择最近的 DataNode 建立连接并读取数据
- 如果客户端和其中一个 DataNode 位于同一机器(比如 MapReduce 过程中的 mapper 和 reducer),那么就会直接从本地读取数据
- 到达数据块末端,关闭与这个 DataNode 的连接,然后重新查找下一个数据块
- 不断执行第 2~5 步直到数据全部读完
- 客户端调用 close,关闭输入流 DFS InputStream
HDFS 漫画



以上漫画版权均归原图作者所有