LibTorch 上手教程
前言
LibTorch 简介
在 Python 深度学习圈,PyTorch 具有举足轻重的地位。同样的,C++ 平台上的 LibTorch 作为 PyTorch 的纯 C++ 接口,它遵循 PyTorch 的设计和架构,旨在支持高性能、低延迟的 C++ 深度学习应用研究。本文基于 Windows 环境与 Visual Studio 2019 开发工具,将从零开始搭建一个完整的深度学习开发环境,包括环境配置、项目演示、自定义数据集及问题排查等部分。
LibTorch 安装
本文使用的 LibTorch 版本为 LTS(1.8.2) CPU 版,若需要使用 GPU 版,也可以在官方网站下载。
环境配置
创建项目
首先,在 Visual Studio 中创建一个名为 libtorch-toturial 的控制台项目。创建完成后,将项目设置为 Release 模式,x64 平台,如下图。
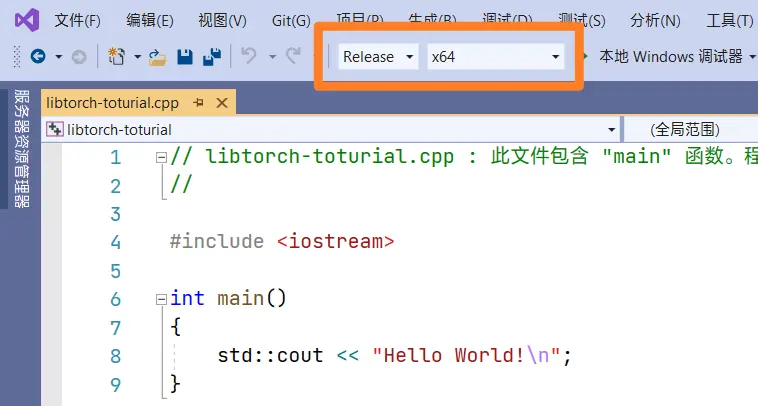
配置 LibTorch 依赖
本文中 LibTorch 解压后的存放目录为 D:\Software\libtorch-lts,后续配置过程中,读者请按照自己实际情况进行相关设置。
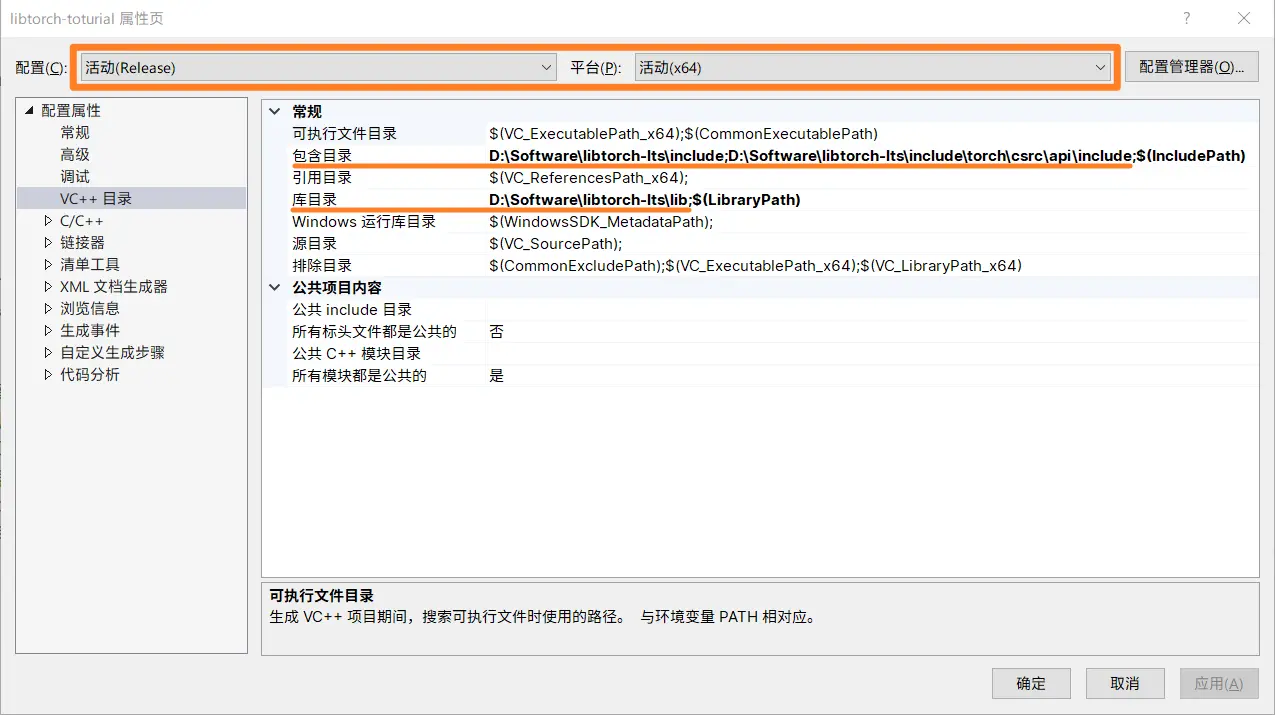
在 Visual Studio 中,点击 项目 -> libtorch-toturial 项目属性,在左侧导航栏中找到 VC++ 目录 选项。在右侧的 包含目录 选项中将 LibTorch include 目录添加进去,详细如下。
1
2
| D:\Software\libtorch-lts\include
D:\Software\libtorch-lts\include\torch\csrc\api\include
|
接着找到 库目录 选项,将 LibTorch lib 目录添加进去,详细如下。
1
| D:\Software\libtorch-lts\lib
|
配置结果如下图,注意检查窗口顶栏 配置 是否为 Release,平台 是否为 x64。
然后找到 链接器 -> 输入 -> 附加依赖项 选项,在其中填入 LibTorch lib 路径下(即 D:\Software\libtorch-lts\lib)所有 *.lib 文件的文件名,详细如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| asmjit.lib
c10.lib
c10d.lib
caffe2_detectron_ops.lib
caffe2_module_test_dynamic.lib
clog.lib
cpuinfo.lib
dnnl.lib
fbgemm.lib
fbjni.lib
gloo.lib
libprotobuf-lite.lib
libprotobuf.lib
libprotoc.lib
mkldnn.lib
pthreadpool.lib
pytorch_jni.lib
torch.lib
torch_cpu.lib
XNNPACK.lib
|
最后,将 D:\Software\libtorch-lts\lib 路径下所有的 *.dll 文件拷贝至 项目路径 -> x64 -> Release 路径下,如下图。
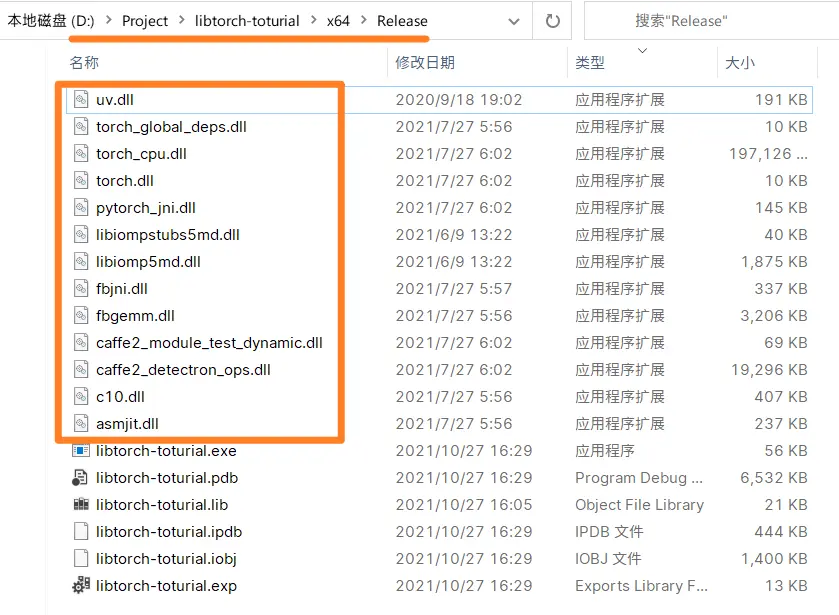
示例程序
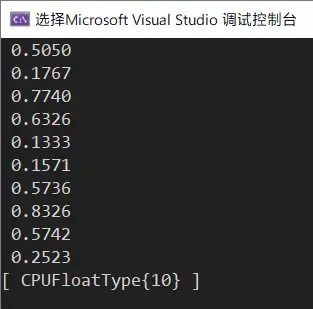
至此,开发环境搭建就已经完成了。我们可以通过运行以下示例程序,来检验上述配置是否正确。若输出如图中所示,则配置无误。
1
2
3
4
5
6
7
| #include <torch/torch.h>
#include <iostream>
auto main() -> int {
auto array = torch::rand(10);
std::cout << array << std::endl;
}
|
手写数字识别
数据准备
本节将以深度学习经典案例——手写数字识别来演示 LibTorch 的使用。首先需要下载 mnist 手写数字数据集,你可以在这里下载,下载完成后将其解压到 libtorch-toturial.cpp 同一目录 data 文件夹下,目录结构如下。
1
2
3
4
5
6
7
8
9
| ├─libtorch-toturial
│ │ libtorch-toturial.cpp
│ │ ...
│ ├─data
│ │ t10k-images-idx3-ubyte
│ │ t10k-labels-idx1-ubyte
│ │ train-images-idx3-ubyte
│ │ train-labels-idx1-ubyte
│ ...
|
源代码
手写数字识别的源代码可以在 LibTorch 官方示例 中找到,请将其拷贝到项目的 libtorch-toturial.cpp 中。
结果
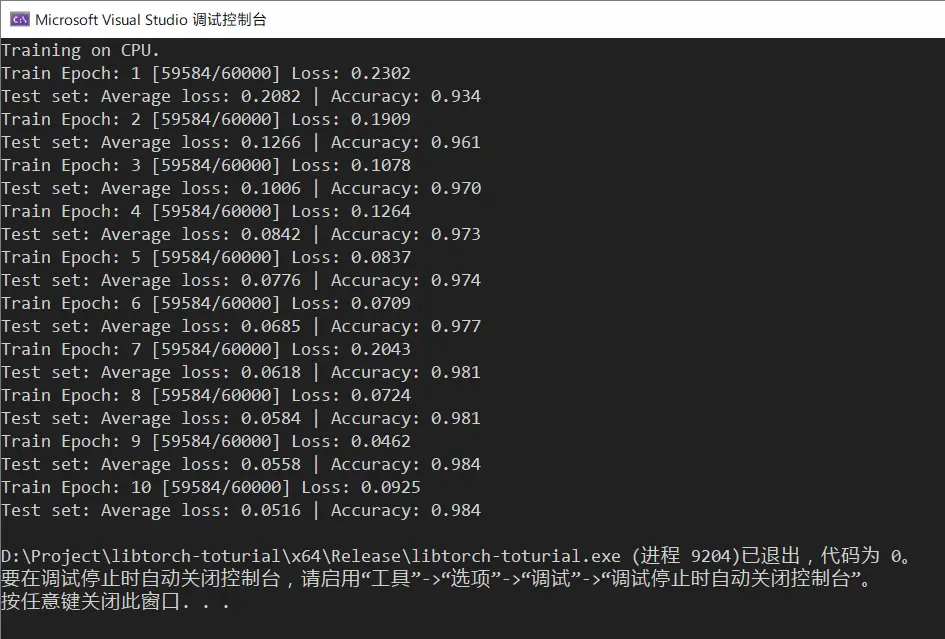
与 PyTorch 类似,LibTorch 创建深度学习应用同样包含与其相似的步骤:定义网络、初始化网络、加载数据集、训练、验证及保存模型等,详细代码可以参照上述官方示例,此处不再赘述。训练 10 个 epoch 之后,识别准确率已经达到了 98.4%.
自定义数据集
在本节中,我们将介绍如何将已有的数据集读取到神经网络中,生成 PyTorch 张量。在这之前,需要先介绍 NumCpp 工具,它可以大幅提升数据处理的效率。
NumCpp 简介与配置
在 Python 开发环境中,最常用的工具非 NumPy 莫属,因其极为便捷高效的特性被开发者广为使用。同样的,在 C++ 平台上,也有开发者开发出了一款与 NumPy 体验“几乎一致”的 NumCpp ———— Python NumPy 库的模板头文件 C++ 实现[2]。
由于 NumCpp 依赖 Boost 库,因此在配置 NumCpp 之前,需要先配置 Boost 库。相关文件可以在 Boost 官方网站 与 NumCpp Github 页面 进行下载。
与 LibTorch 配置过程类似,我们需要在 Visual Studio 项目属性中找到 VC++ 目录 -> 包含目录 选项,将 Boost 库与 NumCpp 库的路径添加进去,具体路径如下。
1
2
| D:\Software\boost
D:\Software\NumCpp\include
|
然后即可使用下述程序片段进行检查是否配置正确,若成功运行并生成了 3x4 个浮点随机数,则说明配置无误。
1
2
3
4
5
6
7
| #include "NumCpp.hpp"
#include <iostream>
auto main() -> int {
auto array = nc::random::randN<double>({ 3, 4 });
std::cout << array << std::endl;
}
|
接下来可以使用 NumCpp 读取本地数据集,由于 NumCpp 缺少类似于 NumPy 的 loadtxt() 方法,故只能使用 fromfile()方法,具体代码如下。
1
| auto input_data = nc::fromfile<double>(input_filepath, /*sep=*/',');
|
假设数据实际尺寸为 m×n,读取到的数据形状为 1×(m×n),所以还需要进行 reshape() 才可以正常使用。行切片与列切片也和 NumPy 类似,代码如下。
1
2
3
4
5
6
7
| input_data = input_data.reshape(m, n);
// 行切片,形如 input_data = input_data[0:2, :]
input_data = input_data(nc::Slice(0, 2), input_data.cSlice());
// 列切片,形如 input_data = input_data[:, :2]
input_data = input_data(input_data.rSlice(), nc::Slice(0, 2));
|
若要进行矩阵与矩阵的计算,则需要保证矩阵的尺寸一致。若不一致,则可以使用 tile() 方法进行扩充,示例代码如下。
1
2
3
4
5
6
7
8
| // 按列求均值,得到的矩阵为 1×n
auto input_mean = nc::mean(input_data, nc::Axis::ROW);
// 按列求标准差,得到的矩阵为 1×n
auto input_std = nc::stdev(input_data, nc::Axis::ROW);
// 归一化,将 input_mean 与 input_std 扩充为 m×n,再进行操作
input_data = (input_data - nc::tile(input_mean, { input_data.numRows(), 1 }))
/ nc::tile(input_std, { input_data.numRows(), 1 });
|
自定义数据集
要实现自定义数据集,首先要继承 torch::data::Dataset<CustomDataset> 类,实现 CustomDataset() 构造方法、 get() 方法与 size() 方法。示例代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| class CustomDataset : public torch::data::Dataset<CustomDataset> {
private:
std::vector<torch::Tensor> source, target;
public:
// 构造函数
CustomDataset(nc::NdArray<double> input_data, nc::NdArray<double> output_data, std::string data_type) {
// 一些数据读取、处理工作。最后得到的 source 与 target 是输入与输出数据的集合
// 如果要对数据集进行划分,可以在此处声明一个方法进行详细处理
source = process_data(input_data, data_type);
target = process_data(output_data, data_type);
};
// 复写 get() 方法以返回第 index 个位置的张量(输入与输出)
torch::data::Example<> get(size_t index) override {
torch::Tensor sample_source = source.at(index);
torch::Tensor sample_target = target.at(index);
return { sample_source.clone(), sample_target.clone() };
};
// 返回数据的数量
torch::optional<size_t> size() const override {
return source.size();
};
};
|
接下来调用 CustomDataset() 生成 data loader。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| // 训练数据
auto train_dataset = CustomDataset(input_data, output_data, "train_data")
.map(torch::data::transforms::Stack<>());
const size_t train_dataset_size = train_dataset.size().value();
std::cout << "train data size = " << train_dataset_size << std::endl;
// 训练集 data loader
auto train_loader = torch::data::make_data_loader(std::move(train_dataset), train_batch_size);
// 验证数据
auto validate_dataset = CustomDataset(input_data, output_data, "validate_data")
.map(torch::data::transforms::Stack<>());
const size_t validate_dataset_size = validate_dataset.size().value();
std::cout << "validate data size = " << validate_dataset_size << std::endl;
// 验证集 data loader
auto validate_loader = torch::data::make_data_loader(std::move(validate_dataset), validate_batch_size);
|
与手写数字识别示例类似,在调用 train() 训练方法和 validate() 验证方法时,直接将 data loader 传入即可,代码示例如下。
1
2
3
4
| for (size_t epoch = 1; epoch <= kNumberOfEpochs; ++epoch) {
train(epoch, model, device, *train_loader, optimizer, train_dataset_size);
validate(model, device, *validate_loader, validate_dataset_size);
}
|
疑难排查
网络浮点数精度
由于上述教程中使用 NumCpp 来读取数据,得到的数据集数据类型为泛型中指定的类型。LibTorch 网络初始化后的数据类型默认为 float(float32),若我们读取的数据类型为 double(float64) 型,则需要手动将网络数据类型指定为 double,否则程序将会抛出异常[3]。
1
2
| Net model = Net();
model->to(device, torch::kDouble);
|
模型保存再读取异常
当读取本地保存好的模型后,进行预测产生 loss 为 nan 的情况。经过 Debug 查看权重和张量数据,可以发现其均已经溢出了。这可能是由于保存的模型是 double 类型,而重新读取后初始化的模型为 float 类型,导致数据溢出。代码如下。
1
2
3
4
5
6
7
8
9
10
| Net model = Net();
model->to(device, torch::kDouble);
// 数据处理及网络训练与验证,并保存模型
torch::save(model, "test.pt");
Net new_model = Net();
// 首先将网络初始化为 double 类型
new_model->to(device, torch::kDouble);
// 从本地加载保存好的模型
torch::load(new_model, "test.pt");
|
C10 Error
如果在程序运行过程中抛出了 C10 Error,控制台也没有打印出错误信息,这是 LibTorch 一个已知的问题,详见参考文献[4]。为了得到实际的错误信息,此时我们可以使用 try catch 来手动捕获异常,代码如下。
1
2
3
4
5
6
| try {
// 导致异常的代码块
}
catch (std::exception &e) {
std::cout << e.what() << std::endl;
}
|
参考文献
- LibTorch 教程 - Allent Dan
- NumCpp 官方文档
- Does LibTorch not support float64 data training?
- After torch::load model and predict, then got NaN