MapReduce 分布式编程
词频统计程序示例
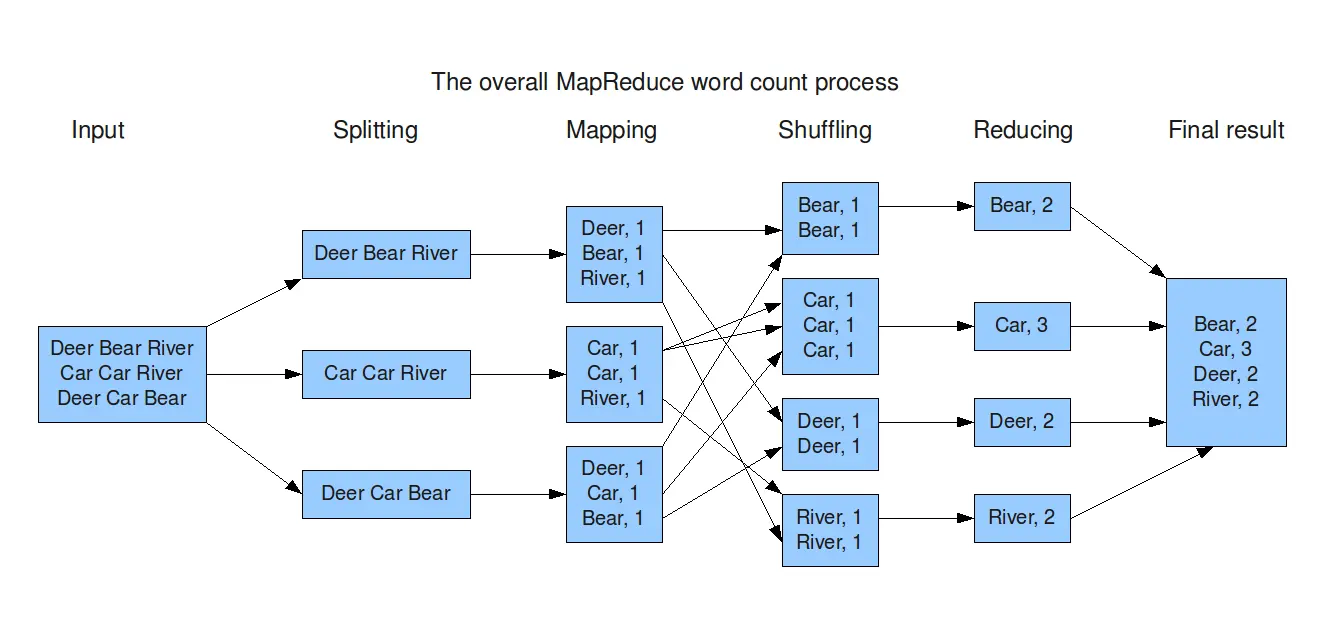
假设将一个英文文本大文件作为输入,统计文件中单词出现的频数。最基本的操作是把输入文件的每一行传递给 map 函数完成对单词的拆分并输出中间结果,中间结果为 <word, 1> 的形式, 表示程序对一个单词,都对应一个计数 1。使用 reduce 函数收集 map 函数的结果作为输入值,并生成最终 <word, count> 形式的结果,完成对每个单词的词频统计。它们对应 MapReduce 处理数据流程如上图所示。
MapReduce 程序的运行过程
如图所示,MapReduce 运行阶段数据传递经过输入文件、Map 阶段、中间文件、 Reduce 阶段、输出文件五个阶段,用户程序只与 Map 阶段和 Reduce 阶段的 Worker 直接相关,其他事情由 Hadoop 平台根据设置自行完成。
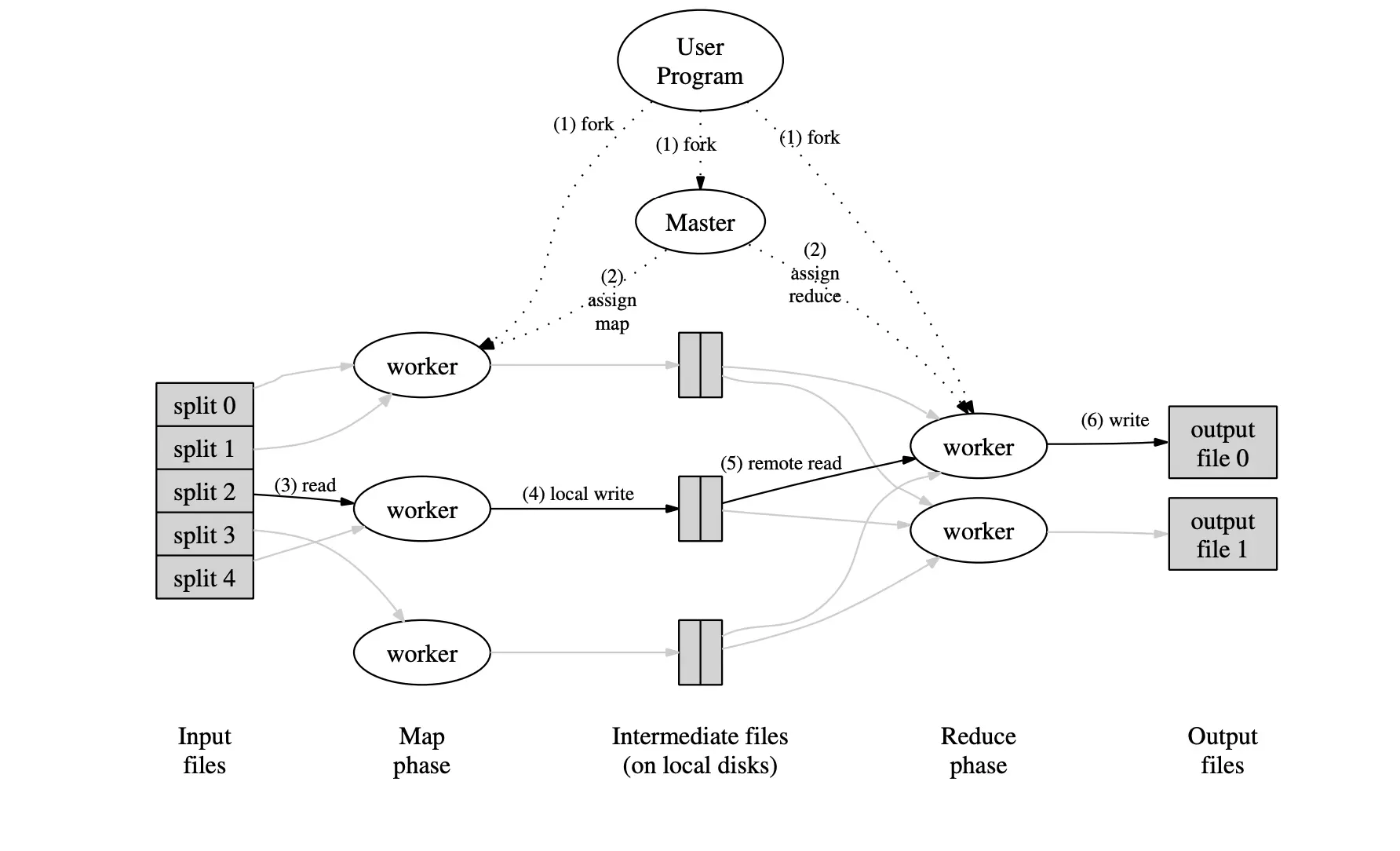
从用户程序 User Program 开始,用户程序 User Program 链接了 MapReduce 库,实现了最基本的 map 函数和 reduce 函数。
- MapReduce 库先把 User Program 的输入文件划分为 M 份,如上图左方所示,将数据分成了分片 0
4,每一份通常为 16MB64MB;然后使用 fork 将用户进程复制到集群内其他机器上。 - User Program 的副本中有一个 Master 副本和多个 Worker 副本。Master 是负责调度的,为空闲 Worker 分配 Map 作业或者 Reduce 作业。
- 被分配了 Map 作业的 Worker,开始读取对应分片的输入数据, Map 作业数量与输入文件划分数 M 相同,并与分片一一对应; Map 作业将输入数据转化为键值对表示形式并传递给 map 函数,map 函数产生的中间键值对被缓存在内存中。
- 缓存的中间键值对会被定期写入本地磁盘,而且被分为 R 个区(R 的大小是由用户定义的),每个区会对应一个 Reduce 作业;这些中间键值对的位置会被通报给 Master, Master 负责将信息转发给 Reduce Worker。
- Master 通知分配了 Reduce 作业的 Worker 负责数据分区,Reduce Worker 读取键值对数据并依据键排序,使相同键的键值对聚集在一起。同一个分区可能存在多个键的键值对,而 reduce 函数的一次调用的键值是唯一的, 所以必须进行排序处理。
- Reduce Worker 遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给 reduce 函数,reduce 函数产生的输出会写回到数据分区的输出文件中。
- 当所有的 Map 和 Reduce 作业都完成了,Master 唤醒 User Program,MapReduce 函数调用返回 User Program。
执行完毕后,MapReduce 的输出放在 R 个分区的输出文件中,即每个 Reduce 作业分别对应一个输出文件。用户可将这 R 个文件作为输入交给另一个 MapReduce 程序处理,而不需要主动合并这 R 个文件。在 MapReduce 计算过程中,输入数据来自分布式文件系统,中间数据放在本地文件系统,最终输出数据写入分布式文件系统。
必须指出 Map 或 Reduce 作业和 map 或 reduce 函数存在以下几个区别:
- Map 或 Reduce 作业是从计算框架的角度来认识的,而 map 或 reduce 函数是需要程序员编写代码完成的,并在运行过程中被对用 Map 或 Reduce 作业调度;
- Map 作业处理一个输入数据的分片,可能需要多次调用 map 函数来处理输入的键值对;
- Reduce 作业处理一个分区的中间键值对,期间要对每个不同的键调用一次 reduce 函数,一个 Reduce 作业最终对应一个输出文件。
经典 MapReduce 任务调度模型
经典 MapReduce 任务调度模型采用主从结构(Master/Slave),包含四个组成部分:Client、JobTracker、TaskTracker、Task。支撑 MapReduce 计算框架的是 JobTracker 和 TaskTracker 两类后台进程。框架结构如下图所示。
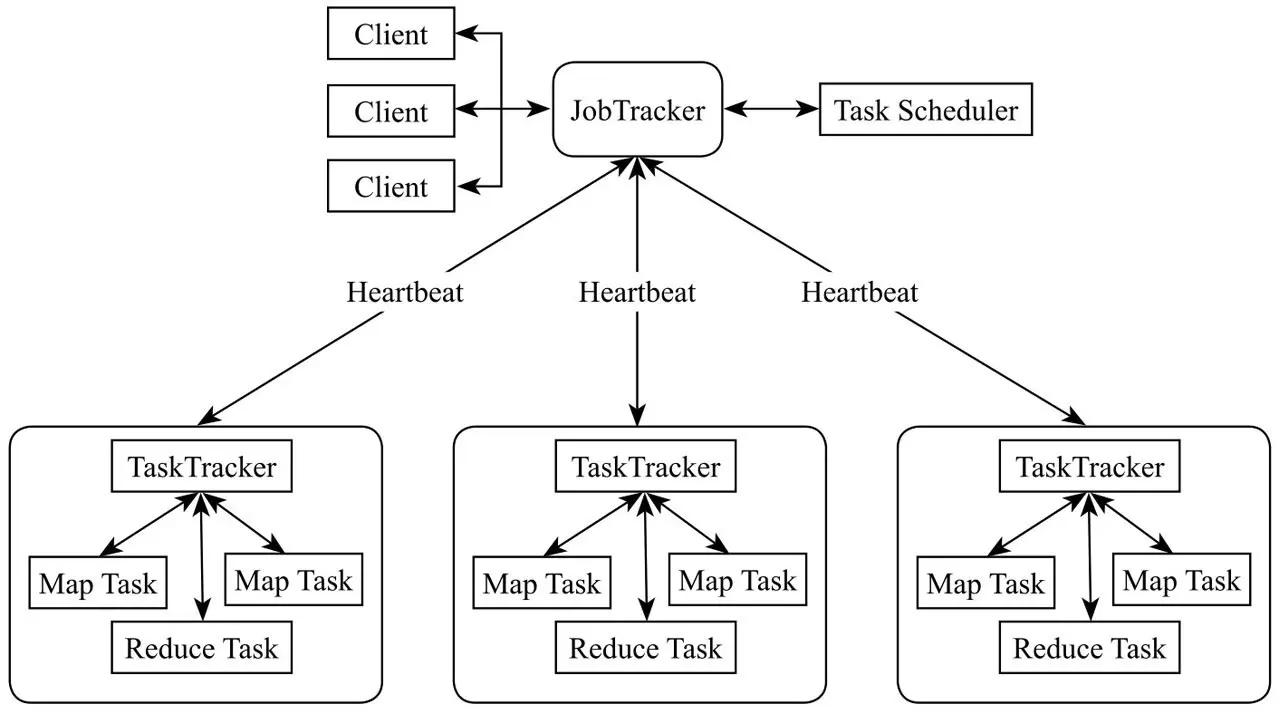
- Client 每一个 Job 在 Ciat 端将运行 MapRecdce 程序所需要的所有 Jar 文件和类的集合,打包成一个 Jar 文件存储在 HDFS 中,并把文件路径提交到 JobTracker。
- JobTracker JobTracker 主要负责资源的监控和作业调度,一个 Hadoop 集群只有一个 JobTracker,并不参与具体的计算任务。根据提交的 Job,JobTackor 会创建一系列 Task(即 MapTask、ReduceTask),分发到每个 TaskTracker 服务中去执行。常用的作业调度算法主要包括 FIFO(First In First Out) 调度器(默认)、公平调度器、容量调度器等。
- TaskTracker TaskTracker 主要负责汇报心跳和执行 JobTracker 分发的任务。TaskTracker 会周期性地通过 HeartBeat 将本节点上资源的使用情况和任务的运行进度汇报给 JobTracker,JobTracker 会根据心跳信息和当前作业运行情况为 TaskTracker 下达任务,主要包括启动任务、提交任务、杀死任务和重新初始化命令等。
- Task Task 分为 MapTask 和 ReduceTask 两种,均由 TaskTracker 启动,执行 JobTracker 分发的任务。MapTask 解析每条数据记录,传递给用户编写的 map 函数并执行,最后将输出结果写入 HDFS;ReduceTask 从 MapTask 的执行结果中,对数据进行排序,将数据按分组传递给用户编写的 reduce 函数执行。
TaskTracker 分布在 Map-Reduce 集群每个节点上,主要是监视所在机器的资源情况和当前机器的 tasks 运行状况。TaskTracker 通过 HeartBeat 发送给 JobTracker,JobTracker 会根据这些信息给新提交的 job 分配计算节点。经典 MapReduce 框架 MR V1 模型简单直观,但是不能满足大规模集群任务调度的需要。主要表现为以下四点:
- JobTracker 是 MapReduce 的集中处理点,存在单点故障问题;
- 当 MapRcduce job 非常多的时候,会造成很大的内存开销,就增加了 JobTracker 失败的风险,业界普遍认为该调度模型支持的上限为 4000 个节点;
- 在 TaskTracker 端,以 Map/Reduce Task 的数目作为资源的表示过于简单,没有考虑到 CPU/内存的占用情况,如果两个大内存消耗的 Task 被调度到一起, 就很容易出现内存消耗殆尽的问题;
- TaskTracker 把资源强制划分为 Map Task Slot 和 Reduce Task Slot,如果当系统中只有 Map Task 或者只有 Reduce Task 时,会造成资源的浪费,导致集群资源利用不足。
YARN 框架原理及运行机制
为了从根本上解决经典 MapReduce 框架的性能瓶颈,Hadoop 的 MapReduce 框架完全重构,叫做 YARN 或者 MR V2。
YARN 的基本思想就是将经典调度框架中 JobTracker 的资源管理和任务调度/监控功能分离成两个单独的组件,即一个全局的资源管理器 ResoureManager 和每个应用程序特有的 ApplicationMaster。ResoureManager 负责整个系统资源的管理和分配,而 ApplicationMaster 则负责单个应用程序的资源管理。
YARN 调度框架包括 ResourceManager、ApplicationMaster、NodeMananger 及 Container 等组件概念。
ResourceManager 是基于应用程序对资源的需求进行调度的。每一个应用程序需要不同类型的资源,因此就需要不同的容器。这些资源包括内存、CPU、磁盘、网络等。 ApplicationMaster 负责向调度器申请、释放资源,清求 NodeManager 运行任务、跟踪应用程序的状态和监控它们的进程。
NodeManager 是 YARN 中单个节点的代理,负责与应用程序的 ApplicationMaster 和集群管理者 ResourceManager 交互;从 ApplicationMaster 上接收有关 Container 的命令并执行(例如,启动、停止 Container);向 ResourceManager 汇报各个 Container 执行状态和节点健康状况,并读取有关 Container 的命令;执行应用程序的容器、监控应用程序的资源使用情况并且向 ResourceManager 调度器汇报。
Container 是 YARN 中资源的抽象,它封装了节点上一定量的资源(CPU 和内存等)。一个应用程序所需的 Container 分为两类:一类是运行 ApplicationMaster 的 Container,是由 ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的 ApplicationMaster 所需的资源;另一类是运行各类任务的 Container,是由 ApplicationMaster 向 ResourceManager 申请的,并由 ApplicationMaster 与 NodeManager 通信后启动。
用户向 YARN 提交一个应用程序后,YARN 将分为两个阶段运行该应用程序:第一个阶段是启动 ApplicationMaster;第二个阶段是由 ApplicationMaster 创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行成功。
YARN 任务调度流程如下图所示。
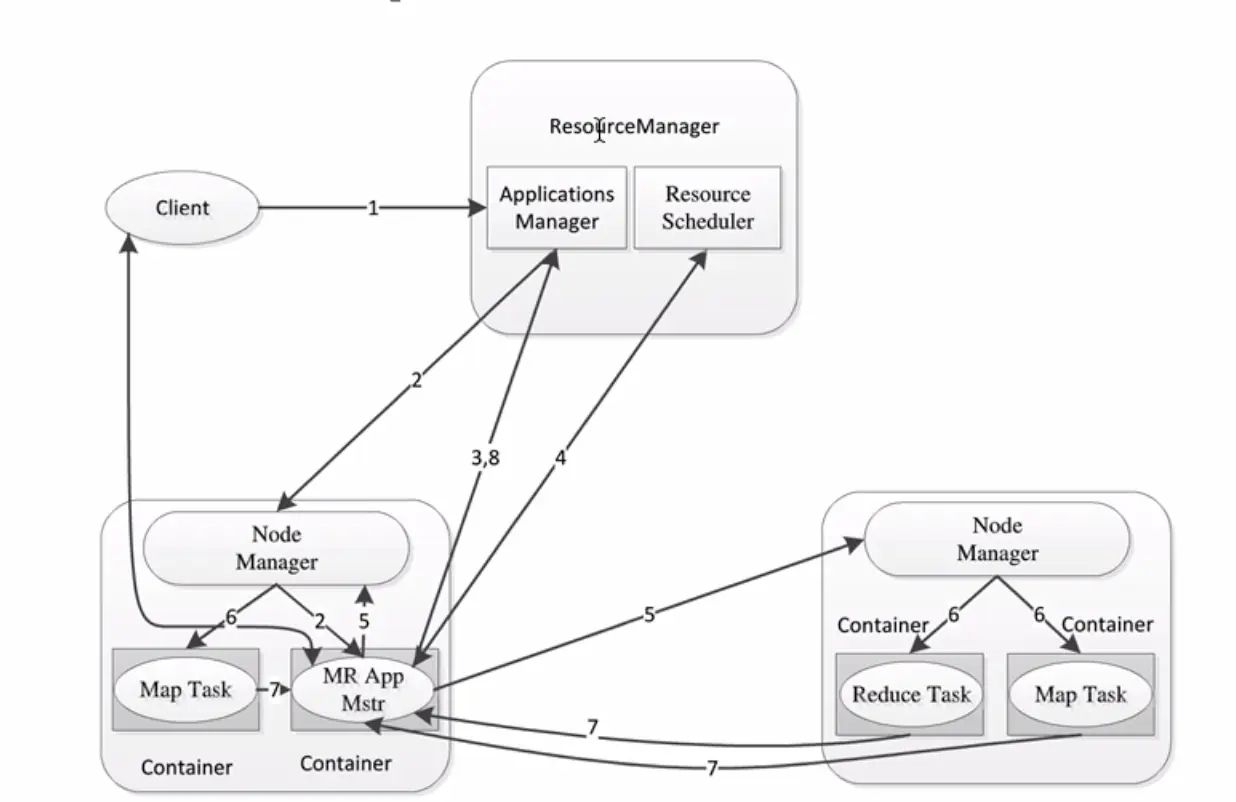
- 用户向 YARN 提交应用程序;
- ResourceManager 为该应用程序在某个 NodeManagr 分配一个 Container,并要求 NodeManager 启动应用程序的 ApplicationMaster;
- ApplicationMaster 启动后立即向 ResourceManager 注册,此时用户可以直接通过 ResourceManager 查看应用程序的运行状态,然后它将为各个任务申请分布在某些 NodeManager 上的容器资源,并监控它的运行状态(步骤 4~7),直到运行结束;
- ApplicationMaster 采用轮询的方式向 ResourceManager 申请和领取资源;
- ApplicationMaster 申请到资源后,即与资源容器所在的 NodeManager 通信,要求其在容器内启动任务;
- NodeManager 为任务初始化运行环境(包括环境变量、jar 包、二进制程序等),启动任务;
- 运行各个任务的容器通过向 ApplicationMaster 汇报自己的状态和进度,使 ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。用户可以向 ApplicationMaster 查询应用程序的当前运行状态;
- 应用程序运行完成后,ApplicationMaster 向 ResourceManager 注销并关闭。
YARN 框架和经典的 MRV1 调度框架相比,主要有以下优化:
- ApplicationMaster 使得检测每一个 Job 子任务状态的程序分布式化,减少了 JobTracker 资源消耗;
- 在 YARN 中,用户可以对不同的编程模型写自己的 ApplicationMaster, 可以让更多类型的编程模型运行在 Hadoop 集群上,如 Spark 基于内存的计算模型;
- Container 提供 Java 虚拟机内存的隔离,优化了经典调度框架中 Map Slot 和 Reduce Slot 分开造成集群资源闲置的不足。
Youtube 数据集统计分析
本例的数据来自于 Youtube 的数据集,完整的数据集以及源代码下载地址请点击以下链接 https://github.com/jinggqu/BigDataTechnologyFoundation-SourceCodeAndDataSet/blob/main/ch04
该数据集各字段的具体含义如表所示:
| 字段名 | 解释及数据类型 |
|---|---|
| video ID | 视频 ID:每个视频存在唯一的 11 位字符串 |
| uploader | 上传者用户名:字符串类型 |
| age | 视频上传日期与 2007 年 2 月 15 日(YouTube 创立日)的间隔天数:整数值 |
| category | 视频类别:字符串类型 |
| length | 视频长度:整数值 |
| views | 浏览量:整数值 |
| rate | 视频评分:浮点值 |
| ratings | 评分次数:整数值 |
| comments | 评论数:整数值 |
| related IDs | 相关视频 ID,每个相关视频的 ID 均为单独的一列:字符串类型 |
视频类型统计
场景:从已经上传的视频中,统计每一个视频类型下的视频数量。下表所示为数据集数据格式示例。category 列代表了视频类型,因而 map 函数只需逐行读取,返回视频类型为键和数字 1 为值的键值对,再传给 reduce 函数处理即可。map 函数的输入键依然为文本文件中行的偏移量,值为行内容。reduce 函数输出键值对为视频类型和该视频类型中的视频数量。
| video ID | uploader | age | category | length | views | rate | ratings | comments | Related IDs |
|---|---|---|---|---|---|---|---|---|---|
| PRGUU_ggO3k | tom | 704 | Entertainment | 262 | 11235 | 3.86 | 247 | 280 | tpAL3iOurl4…ifn1njiY4s |
| RX24KLBhwMI | jsack | 687 | Blogs | 512 | 24149 | 4.22 | 315 | 474 | PkGUU_ggO3k…tpAl3iOurl4 |
Mapper 类代码实现
| |
第 2 行构造 IntWritable 可持久化对象并赋值为 1;第 8~10 行过滤字段,将一条记录中的分类 category 作为 map 函数的 value 输出。
Reduce 类代码实现
| |
reduce 函数接收 Map 阶段传来的键值对,第 3~6 行遍历每一组记录,累加同一视频类型下的视频数量,第 7 行通过 context 输出计算结果。
运行
- 通过 IDEA-Build-Build Artifacts 功能将代码打包为 jar 文件,命名为 CategoryCount.jar
- 登录 Hadoop 集群,将数据集文件 YoutubeDataSets.txt 传到 HDFS 下 /tmp 目录下
- 执行如下命令,开始运行程序
| |
- 执行如下命令,查看各类别视频数量
| |
可以得到如下输出
UNA 32
Autos & Vehicles 77
Comedy 420
Education 65
Entertainment 911
Film & Animation 261
Howto & Style 138
Music 870
News & Politics 343
Nonprofits & Activism 43
People & Blogs 399
Pets & Animals 95
Science & Technology 80
Sports 253
Travel & Events 113