并行计算总结
1. 概念
1.1 摩尔定律(Moore’s law)
摩尔定律是由英特尔(Intel)创始人之一戈登·摩尔提出的。其内容为:集成电路上可容纳的晶体管数目,约每隔两年便会增加一倍;经常被引用的“18 个月”,是由英特尔首席执行官大卫·豪斯(David House)提出:预计 18 个月会将芯片的性能提高一倍(即更多的晶体管使其更快),是一种以倍数增长的观测。
通常认为摩尔定律具体的内容:每 18 个月,芯片的性能将提高一倍。
1.2 新摩尔定律(存疑)
由于单个核心性能提升有着严重的瓶颈问题,未来的计算机硬件不会更快,但会更“宽”。
1.3 常见并行模式
进程 + 线程 硬件组织通常是多机+多核,编程环境 MPI+OpenMP
线程 + GPU 线程 硬件组织通常是多核+多 GPU,编程环境 OpenMP+CUDA/OpenCL
进程 + 线程 + GPU 线程 硬件组织通常是多机+多核+多 GPU,编程环境 MPI+OpenMP+CUDA/OpenCL
1.4 CPU 与 GPU 区别
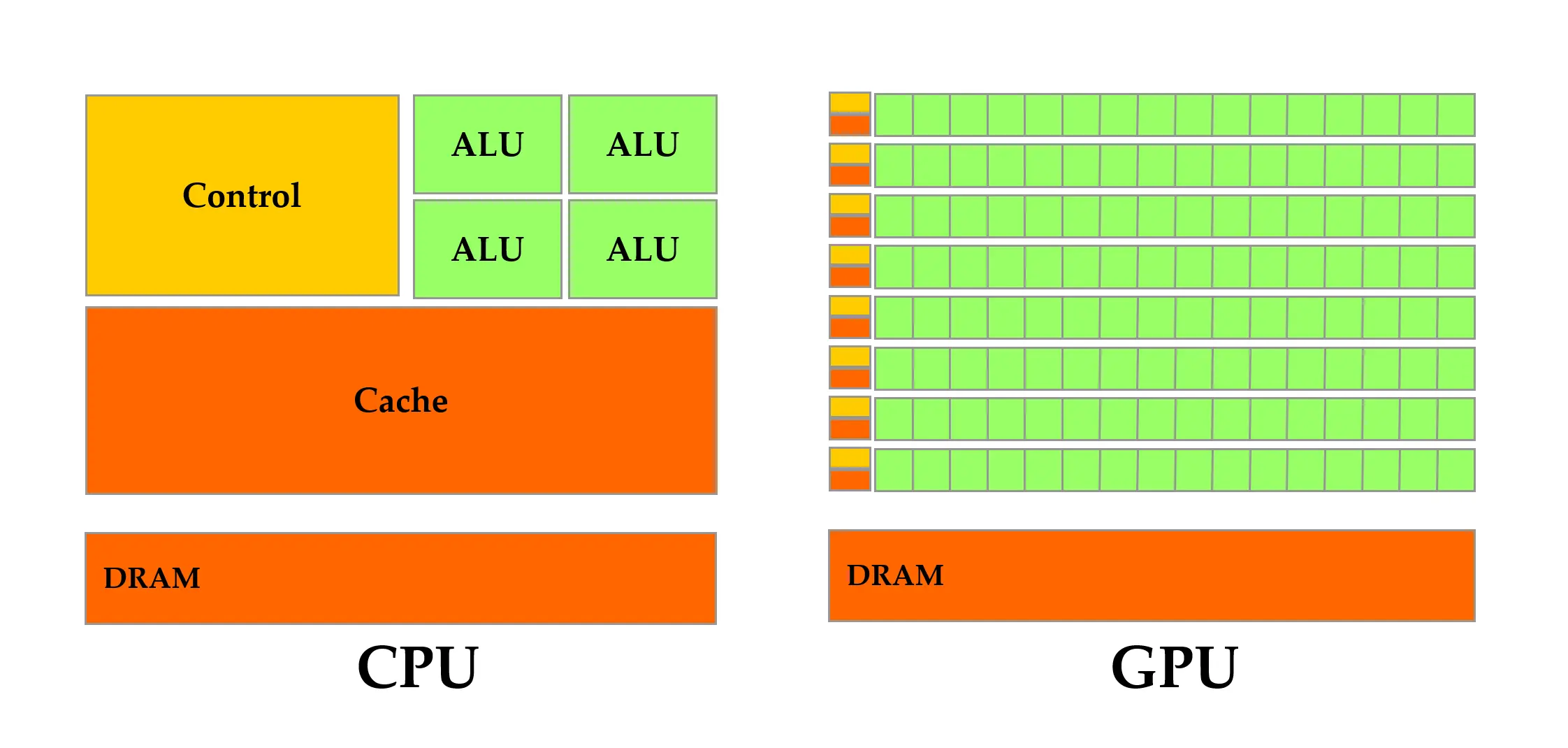
上图中,绿色的是计算单元,橙红色的是存储单元,橙黄色的是控制单元。其中,各个部件详细释义:
- ALU:算术逻辑单元(Arithmetic Logic Unit),是一种可对二进制整数执行算术运算或位运算的组合逻辑数字电路;
- Control:控制单元,负责指挥 CPU 工作,控制其他设备的活动;
- Cache:用于减少处理器访问内存所需平均时间的部件;
- DRAM:动态随机存取存储器(Dynamic Random Access Memory),即内存。
简而言之,CPU 擅长于复杂逻辑控制,GPU 擅长于简单重复运算。
2. CUDA 简介及架构
CUDA(Compute Unified Device Architecture)是 NVIDIA 推出的的通用并行计算架构,该架构使 GPU 能够解决大量重复性的计算问题。
2.1 物理架构
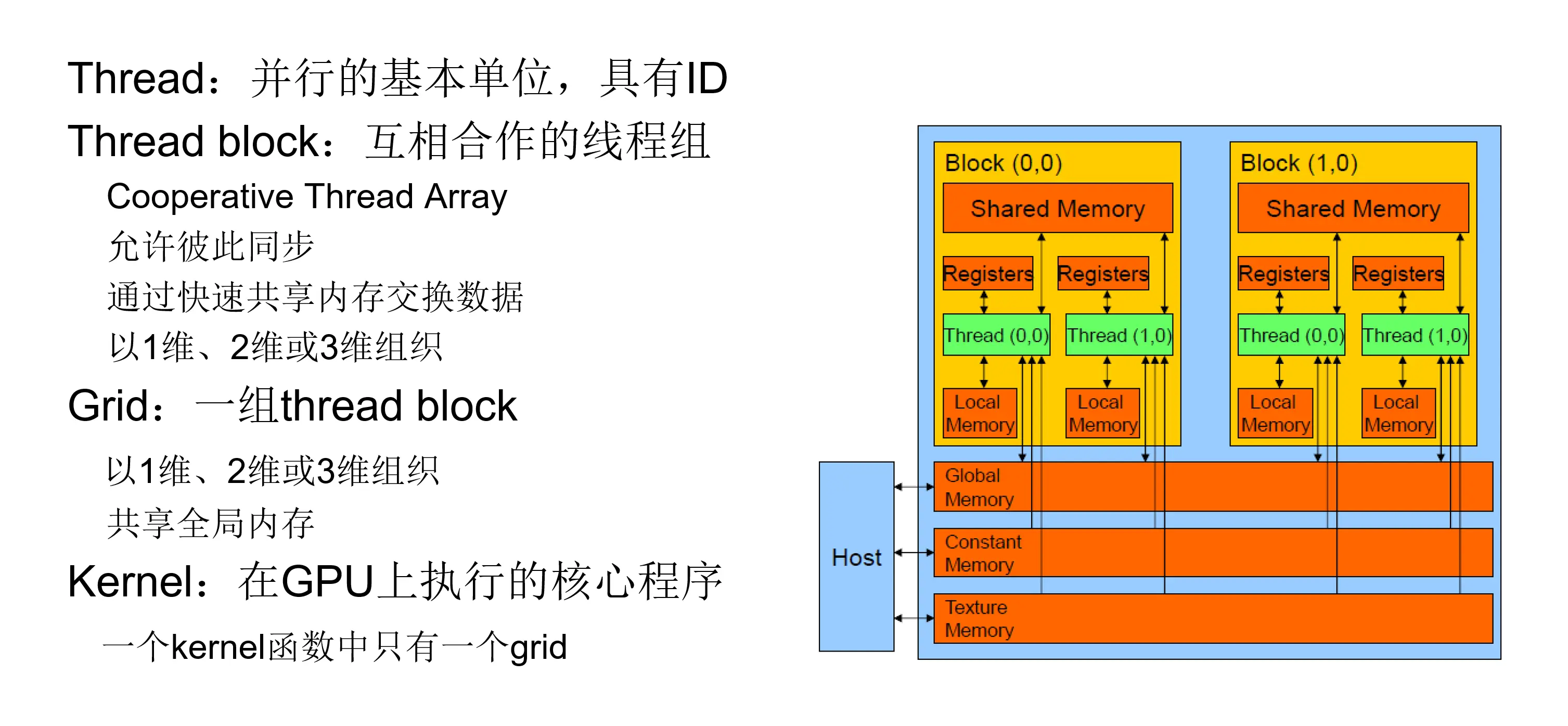
2.2 kernel 函数启动参数
2.2.1 blocksPerGrid
用于定义 kernel 函数使用的 block 数量,可以定义为一、二与三维结构,示例如下;
| |
2.2.2 threadsPerBlock
用于定义每个 block 中使用的线程数量,与 block 类似,同样可以定义为一、二与三维结构。在目前的 GPU 上,一个线程块可以包含多达 1024 个线程。示例如下;
| |
2.2.3 调用 kernel 函数
| |
2.3 常用 CUDA 关键字
| 函数定义方式 | 执行方 | 调用方 |
|---|---|---|
| __device__ float DeviceFunc() | GPU | GPU |
| __global__ void KernelFunc() | GPU | CPU |
| __host__ float HostFunc() | CPU | CPU |
__device__函数没有函数地址,也没有指向它的函数指针。在 device 端执行的函数有下面的限制:
- 没有递归;
- 函数内部没有静态变量;
- 参数的数量是固定的。
2.3.1 __shared__
- 存储于 GPU 上的 thread block 内的共享存储器;
- 和 thread block 具有相同的生命期;
- 只能被 thread block 内的线程存取。
常用于声明变量,声明后的变量将会存储在 shared memory 中,例如
| |
2.4 内存类型
2.4.1 Register 与 Local Memory
- 对每个线程来说,寄存器都是线程私有的;
- 如果寄存器被消耗完,数据将被存储在 local memory。Local memory 是私有的,但是 local memory 中的数据是被保存在显存中,速度很慢;
- 输入和中间输出变量将被保存在 register 或者 local memory 中。
2.4.2 Shared Memory
- 用于线程间通信的 shared memory。shared memory 是一块可以被同一 block 中的所有 thread 访问的可读写存储器;
- 访问 shared memory 几乎和访问 register 一样快,是实现线程间通信的延迟最小的方法;
- shared memory 可以实现许多不同的功能,如用于保存公用的计数器或者 block 的公用结构。
2.5 内存分配
通过如下语句可以实现 CUDA 内存分配,分配显存中的 global memory。
| |
其中
- devPtr:对象指针;
- size:分配的内存大小。
例如
| |
通过如下语句可以实现 CUDA 释放 global memory 中分配出的内存。
| |
2.6 数据交换
通过如下语句可以实现 CUDA 显存中数据与 CPU 内存端数据的交换。
| |
其中
- dst:目的存储器地址;
- src:源存储器地址;
- count:拷贝数据的大小;
- kind:数据传输类型,常用的包括以下两种: cudaMemcpyDeviceToHost:将显存中的数据拷贝到内存中; cudaMemcpyHostToDevice:将内存中的数据拷贝到显存中。
例如
| |
2.7 线程同步
2.7.1 block 内线程同步
通过调用以下方法,实现同一个 block 内所有线程同步。
| |
例如
| |
2.7.2 CPU 与 GPU 线程同步
通常情况下,CPU 端调用 kernel 函数,并不会阻塞后续 CPU 端的代码执行,也即调用 kernel 函数是异步的。若要实现同步的效果,只需在调用 kernel 函数后调用以下方法,进行线程同步即可。
| |
例如
| |
3 CUDA 编程
3.1 矩阵相加
https://github.com/jinggqu/ParallelComputing/blob/main/classwork/01/matrix_addition.cu
3.2 矩阵相乘
https://github.com/jinggqu/ParallelComputing/blob/main/classwork/02/matrix_multiplication.cu